Showdown of Whisper Variants
Showdown of Whisper Variants
In the realm of speech recognition technology, Whisper stands out as a widely used model for converting speech to text. As we aim to identify the most effective solution for transcription tasks while considering resource efficiency, the evaluation of various models becomes crucial. This blog post undertakes a comparative analysis of Whisper, Faster Whisper, Whisper.cpp, and Insanely Fast Whisper, all competing to excel in accurately transcribing Urdu audio from multiple speakers. Each model offers distinct approaches, promising enhanced performance and efficiency in handling complex languages like Urdu. Let's explore the strengths and limitations of each model to determine their suitability for Urdu speech recognition.
Overview
Before diving into the comparison, it's crucial to understand the nuances and capabilities of each whisper variant being evaluated. Below, we provide a brief overview of four variants — OpenAI Whisper, Faster Whisper, Whisper.cpp, and Insanely Fast Whisper—each offering unique features and optimizations.
1. OpenAI Whisper:
Whisper is a versatile speech recognition model developed by OpenAI. Trained on a vast and diverse dataset, Whisper boasts multitasking capabilities, including multilingual speech recognition, speech translation, and language identification. Utilizing a Transformer sequence-to-sequence architecture, Whisper can replace multiple stages of traditional speech-processing pipelines, offering a comprehensive solution for various speech-related tasks.
2. Faster Whisper:
Faster Whisper is a reimplemented version of OpenAI's Whisper model, leveraging CTranslate2, a fast inference engine for Transformer models. This implementation offers up to four times faster inference speed compared to the original Whisper model, while maintaining the same level of accuracy. With optimizations such as 8-bit quantization on both CPU and GPU, Faster Whisper presents an efficient solution for real-time speech recognition applications.
3. Whisper.cpp:
Whisper.cpp is an alternative implementation of the original Whisper model by OpenAI. Developed in C/C++, Whisper.cpp runs initially used exclusively on the CPU but has now added cuda support. It aims to provide similar functionality as the Python-based Whisper model while making it resource efficient for CPU and GPU which offer advantages in certain scenarios, such as on performing transcription on edge devices.
4. Insanely Fast Whisper:
Insanely Fast Whisper is a transcription tool powered by OpenAI's Whisper Large V3 technology, designed for swift and accurate transcription of audio files. This tool includes a command-line interface (CLI) and an inference API, along with optimizations such as batching, beam size adjustment, and flash attention. With its focus on speed and efficiency, Insanely Fast Whisper caters to users seeking rapid transcription capabilities for diverse speech recognition tasks.
Experimental Setup
For our experimental setup, we employed a 26-minute-long audio recording capturing a non-scripted conversation involving five speakers, consisting of four females and one male. This diverse audio dataset aimed to simulate real-world conditions, reflecting the variability in speech patterns and accents commonly encountered in multispeaker environments.
The experiments were conducted using Google Colab's cloud-based infrastructure, with access to a computational resource featuring a T4 GPU for efficient model inference. The setup aimed to leverage parallel processing capabilities offered by the GPU to expedite model computations and enhance overall performance.
By utilizing this setup, we aimed to evaluate the performance of each whisper variant under consistent hardware conditions, ensuring fair comparisons across different models. The choice of dataset and hardware configuration was intended to mimic real-world scenarios while optimizing computational resources for efficient experimentation and analysis.
Performance in Transcription
Overall, the models exhibited varying degrees of effectiveness in transcribing Urdu audio content. While most models successfully captured the entirety of the audio, one notable exception was Whisper.cpp, which lagged behind, only managing to transcribe approximately 25% of the content accurately.
Script Consistency:
A noteworthy observation was the handling of script consistency across the models. OpenAI Whisper and Whisper.cpp adeptly adhered to the Arabic script, commonly used for writing Urdu. Conversely, Faster Whisper and Insanely Fast Whisper tended to retain English words in Latin script. For instance, the phrase "ابھی recording ہو رہی ہوگی" was accurately transcribed as such by Whisper.cpp, while Faster Whisper rendered it as "ابھی recording ہو رہی ہوگی".
The choice between maintaining script consistency or allowing transliteration depends on the specific use case and preferences of the user.
Challenges with Hallucinations:
A prevalent challenge encountered across all models was the occurrence of hallucinations, particularly following periods of silence. This phenomenon resulted in the models becoming stuck on previous inputs, often repeating entire lines or individual words incessantly.
Hallucination Statistics:
In cases where the lines were repeated multiple times. Here is how the models performed
OpenAI Whisper: 176 out of 412 lines were repeated.
Faster Whisper: 155 out of 344 lines were repeated.
Whisper.cpp: 1046 out of 1545 lines were repeated.
Insanely Fast Whisper: 72 out of 196 lines were repeated.
Additionally, OpenAI Whisper repeated the same words in 4 lines, Faster Whisper in 3 lines, Whisper.cpp in 2 lines, and Insanely Fast Whisper in 11 lines.

OpenAI Whisper and Faster Whisper exhibited similar performance in managing hallucinations. In contrast, Insanely Fast Whisper had a lower sentence repetition rate, although it repeated words within the same sentence more frequently. Conversely, Whisper.cpp performed notably worse, with a 20% higher sentence repetition rate compared to its counterparts
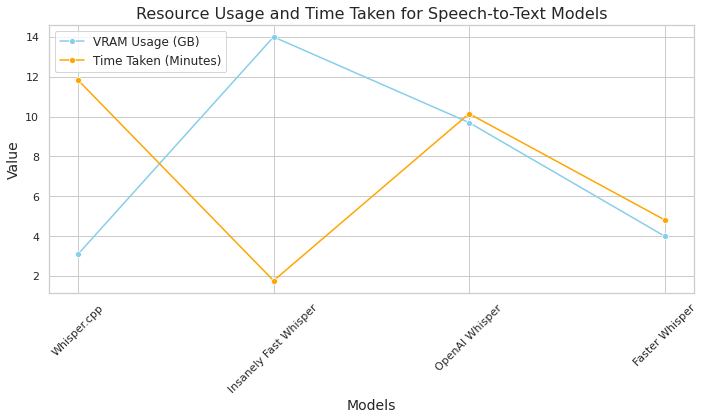
Time and Resource Comparison:

The Insanely Fast Whisper model ranks highest in time efficiency, followed by Faster Whisper, while Whisper.cpp is the slowest.
In terms of resource efficiency, Whisper.cpp consumes the least VRAM, followed by Faster Whisper, OpenAI Whisper, and Insanely Fast Whisper, in increasing order of resource consumption.
Conclusion
Faster Whisper appears to strike a commendable balance between processing time, resource usage, and performance. However, if time is a constraint and resources are not restricted, Insanely Fast Whisper emerges as the optimal choice, completing tasks in significantly less time despite some compromise in performance.